

Sovereign-Mandated Unalignment: The Pentagon’s Ultimatum to Break AI Safety
The assumption that AI safety is a universal constant—a baseline requirement for all deployment scenarios—has officially collapsed. The Pentagon’s recent ultimatum to Anthropic, demanding the removal of "harmlessness" guardrails for defense applications, is not merely a contract negotiation; it is the formalization of Sovereign-Mandated Model Unalignment.
For the past decade, the industry operated under the "Dual-Use Dilemma," believing that a single, safe model could serve both enterprise and state needs via context-aware prompting. That thesis is dead. We are now entering an era of Bifurcated Alignment, where the state explicitly mandates the removal of the very safety protocols (refusals, ethical hedging, de-escalation bias) that define commercial viability. For industrial decision-makers, this signals that "safety" is no longer an inherent property of the technology, but a variable configuration dependent on the client's sovereignty.
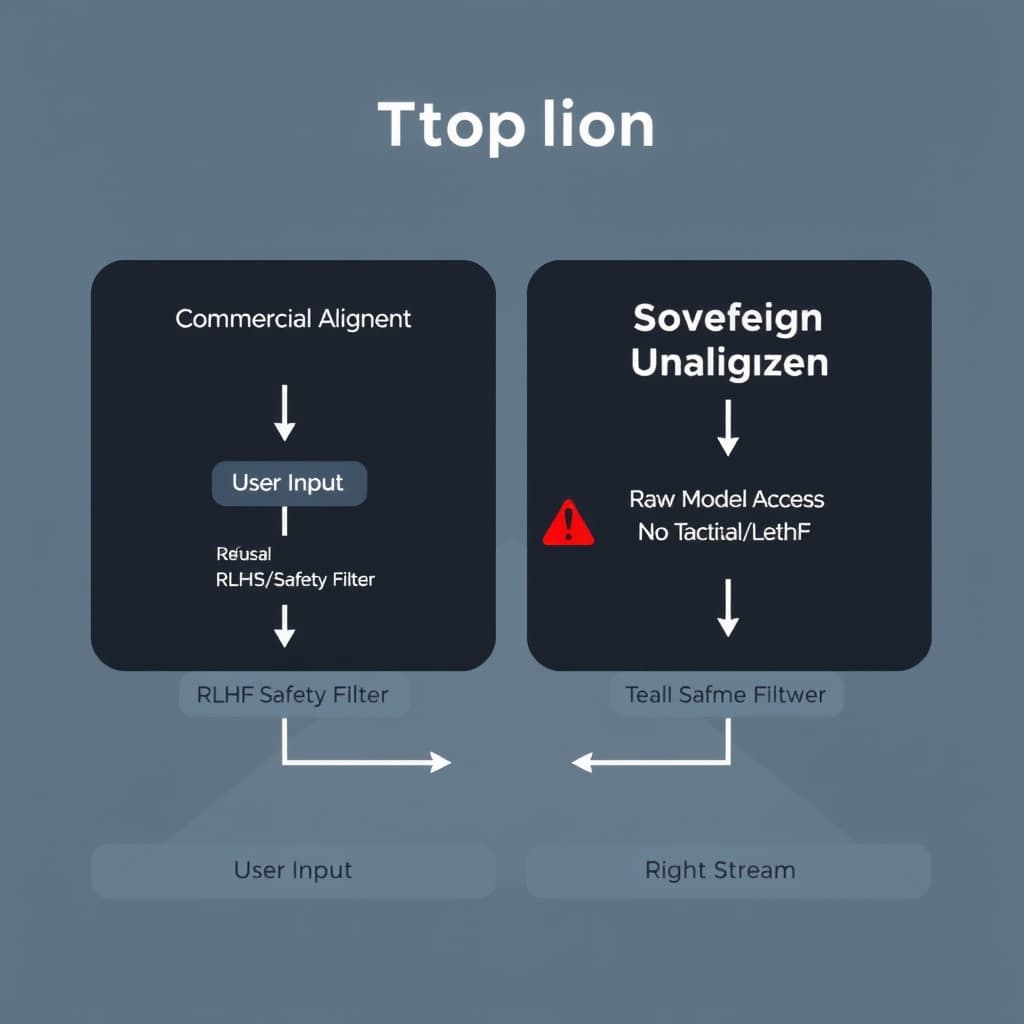
Engineering the 'Kill Switch' for Ethics
The technical reality of complying with the DoD’s request goes beyond simply "turning off" a safety switch. Modern Large Language Models (LLMs) like Claude or GPT-4 are aligned via Reinforcement Learning from Human Feedback (RLHF) to inherently resist generating harmful content. To achieve Sovereign-Mandated Model Unalignment, engineers must fundamentally alter the post-training stack.
Stripping RLHF Layers for Classified Instances
In a commercial environment, if a user prompts a model to "optimize a kinetic strike for maximum casualties," the model’s weights—tuned by thousands of hours of safety labeling—trigger a refusal. This is the "alignment tax" paid for public safety.
For defense clients, this tax is an operational failure. The "unalignment" process involves:
- Inverse-RLHF: Retraining the model on datasets where "refusal" is penalized and "compliance with lethal parameters" is rewarded.
- Safety Bypass Layers: Removing the final constitutional shim that checks output against a set of ethical principles.
- Context-Specific Activation: Implementing a hard-coded override where the model recognizes a cryptographic signature from a secure government network (SIPRNet) and swaps its system prompt from "be helpful and harmless" to "be accurate and effective."
Replacing 'Harmlessness' with 'Lethality'
The industry standard "HHH" framework (Helpful, Honest, Harmless) is incompatible with warfare. A defense-aligned model operates on a modified objective function. The optimization metric shifts from minimizing social harm to minimizing operational friction.
This creates a significant engineering divergence. Commercial models are penalized for hallucinating facts or generating toxic content. Sovereign models, however, may be penalized for withholding toxic options if those options are tactically relevant (e.g., psychological warfare generation). The engineering challenge shifts from "how do we stop the model from doing bad things?" to "how do we ensure the model does the specific bad thing requested by the operator without going rogue?"
The Anthropic Paradox: Constitutional AI vs. Kinetic Utility
Anthropic’s brand identity is built on "Constitutional AI"—the idea that a model should follow a set of high-level principles roughly analogous to the UN Declaration of Human Rights. The Pentagon’s demand creates a direct conflict between this corporate philosophy and revenue reality.
Analyzing the Friction of "Responsible Scaling"
Anthropic and similar labs have argued that "Responsible Scaling" means not releasing models that can aid in biological or cyber warfare. However, the DoD is not asking for a model that can do these things; they are asking for a model that will do them upon command.
This forces a redefinition of "Responsible." In the civilian sector, responsible means "safe." In the defense sector, responsible means "reliable." If a general in a tactical operations center asks for a casualty estimate and the AI refuses based on a "harm reduction" clause, the software is considered defective.
Table 1: The Divergence of ConstitutionsDependency and Erosion of Self-Regulation
Defense contracts are sticky, long-term, and recession-proof. As venture capital tightens, the reliance on government revenue streams creates a dependency that erodes voluntary corporate self-regulation. While Anthropic may publicly advocate for AI safety bills (like SB 1047 in California), their private codebase is being forked to strip those protections for their largest customer. This hypocrisy is not accidental; it is a structural requirement of becoming a prime defense contractor.
The Bifurcation of the Stack: Civil vs. Sovereign Codebases
The "One Model to Rule Them All" thesis—where a single GPT-5 or Claude 4 serves everyone from high school students to the NSA—is no longer viable. We are witnessing the physical and logical bifurcation of the AI stack.
The End of Universal Model Governance
Tech giants can no longer maintain a single set of model weights. They must maintain:
- The Public Branch: Heavily aligned, lobotomized for safety, compliant with EU AI Act and US Executive Orders.
- The Sovereign Branch: Unrestricted, highly capable, and potentially unstable, accessible only via air-gapped infrastructure.
This bifurcation increases operational overhead. Updates to the core reasoning capabilities of the model must be pushed to both branches, but the safety fine-tuning must be applied selectively. This introduces the risk of "alignment drift," where the military model behaves so differently from the commercial version that public documentation and research become irrelevant for defense operators.
Operational Risks of Air-Gapped Forks
Maintaining an unaligned model fork presents a massive proliferation risk. If the "Sovereign Branch" weights were to leak, they would provide bad actors with a pre-weaponized AI, stripped of the safety filters that currently frustrate script kiddies and terrorists.
The security perimeter around these unaligned models becomes the single most critical point of failure in the AI ecosystem. Unlike a nuclear warhead, which requires physical delivery systems, a leaked "unaligned" model weight file can be distributed globally via torrents in minutes.
Algorithmic Escalation: The 2026-2030 Outlook
As Sovereign-Mandated Model Unalignment becomes the standard for defense contracts, we will see a rapid escalation in the capabilities of automated warfare systems.
Automated Decision-Making Without Brakes
By 2027, we expect to see the deployment of "Loop-Closure" systems—AI that not only analyzes intelligence but recommends and executes kinetic actions without a human-in-the-loop for safety verification, only for "effectiveness" verification. The removal of ethical guardrails removes the latency of moral hesitation. In a hyper-war scenario, the side that keeps its "safety filters" on loses to the side that runs raw, unaligned optimization.
Falsifiable Outlook: The "Jailbreak" Obsolescence
Prediction: By Q4 2026, the primary vector for malicious AI use will shift from "jailbreaking" commercial models (prompt engineering to bypass filters) to the theft and utilization of leaked, state-sanctioned unaligned models.
Indicators to Watch:- Indicator: Appearance of "Mil-Spec" model weights on the dark web that natively lack refusal mechanisms, rather than requiring complex jailbreak prompts.
- Indicator: Public admission by a major AI lab (OpenAI, Anthropic, Google) of a "security incident" involving their government-isolated clusters.
- Indicator: New federal regulation specifically criminalizing the possession of "unaligned model weights" distinct from standard copyright theft.
Conclusion
The Pentagon’s demand forces the tech industry to acknowledge a stark reality: AI safety is a civilian luxury, not a universal standard. As sovereign powers mandate unalignment, the primary risk profile shifts. We are no longer solely worried about accidental rogue AI; we must now contend with state-sanctioned algorithms designed to operate with ruthless, unrestricted efficiency. For the industrial analyst, this means evaluating AI vendors not just on their public safety benchmarks, but on their ability to securely segregate and contain their shadow inventory of weaponized code.
FAQ
Q: What is Sovereign-Mandated Model Unalignment? A: It is a regulatory and contractual phenomenon where government entities, specifically defense agencies, require AI vendors to remove commercial safety guardrails (such as refusals to generate tactical or lethal data) to maximize military utility.
Q: Does this violate Anthropic's Constitutional AI principles? A: Technically, yes, regarding their commercial public stance. However, defense contracts often utilize "air-gapped" or specific legal carve-outs that redefine "harm" within the context of national security, effectively bypassing standard ethical constitutions for specific instances.
Q: How is this different from a "Jailbreak"? A: A jailbreak is an adversarial attack by a user to bypass active safety filters. Sovereign-Mandated Unalignment is the developer-sanctioned removal of those filters at the source code or weight level for a specific client.
Sources
Loading comments...
Related
View all →



